Visual language models have evolved significantly recently. However, the existing technology typically only supports one single image. They cannot reason among multiple images, support in context learning or understand videos. Also, they don’t optimize for inference speed.
We developed VILA, a visual language model with a holistic pretraining, instruction tuning, and deployment pipeline that helps our NVIDIA clients succeed in their multi-modal products. VILA achieves SOTA performance both on image QA benchmarks and video QA benchmarks, having strong multi-image reasoning capabilities and in-context learning capabilities. It is also optimized for speed.
It uses 1 ⁄ 4 of the tokens compared to other VLMs and is quantized with 4-bit AWQ without losing accuracy. VILA has multiple sizes ranging from 40B, which can support the highest performance, to 3.5B, which can be deployed on edge devices such as NVIDIA Jetson Orin.
We designed an efficient training pipeline that trained VILA-13B on 128 NVIDIA A100 GPUs in only two days. In addition to this research prototype, we demonstrated that VILA is scalable with more data and GPU hours.
For inference efficiency, VILA is TRT-LLM compatible. We quantized VILA using 4-bit AWQ, which runs at 10ms/token for VILA-14B on a single NVIDIA RTX 4090 GPU.
VILA training recipe
Existing methods like Llava use visual instruction tuning to extend the LLM with visual inputs but lack an in-depth study of the visual language pretraining process, where the model learns to perform joint modeling on both modalities.

Model architecture
Multi-modal LLMs can be categorized into cross-attention-based and auto-regressive-based settings.
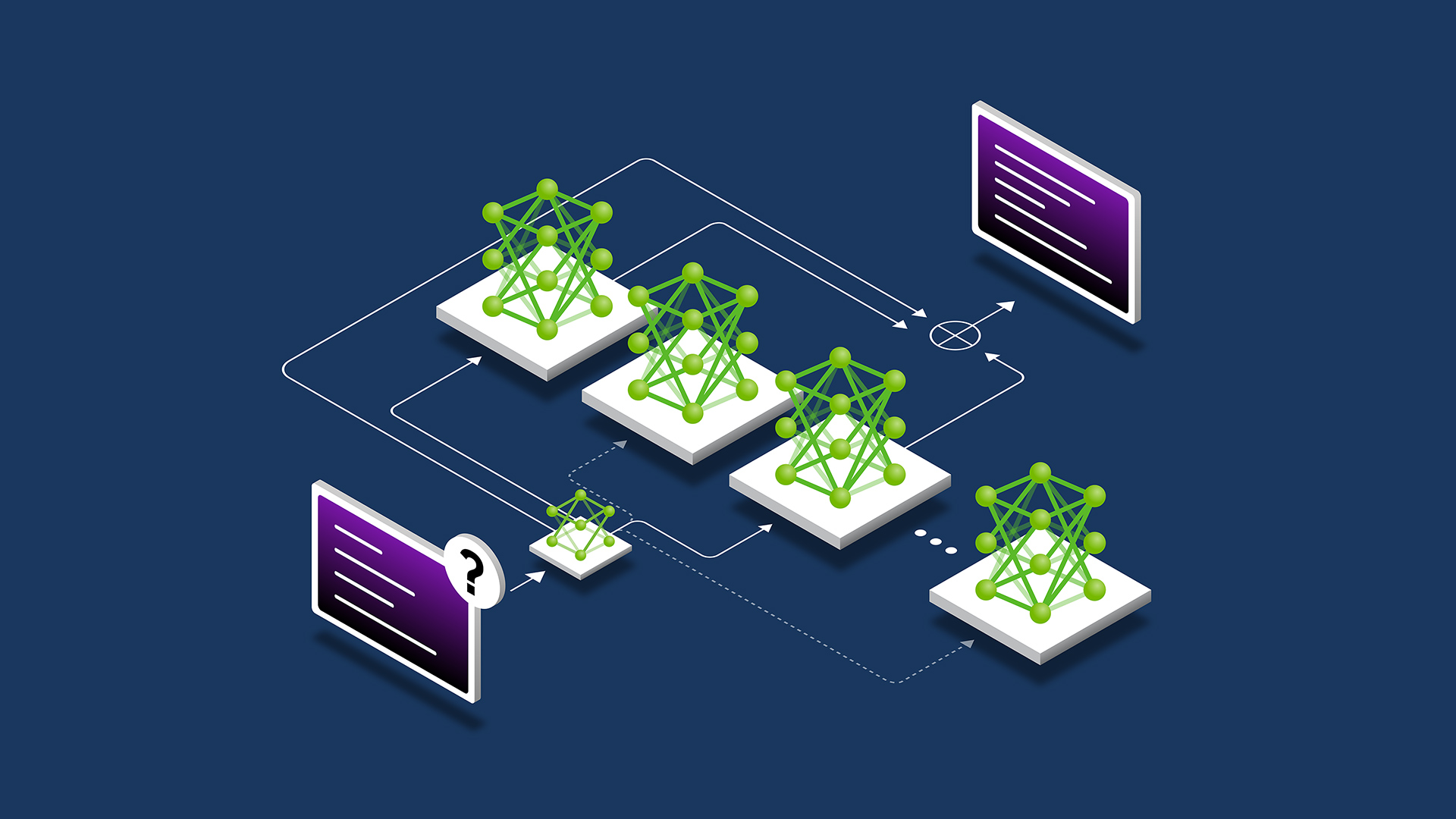
The latter tokenizer converts images into visual tokens, concatenated with textual tokens, and fed as the input to LLMs (that is, treating visual input as a foreign language). It is a natural extension of text-only LLMs by augmenting the input with visual embeddings, similar to RAG, and can handle an arbitrary number of interleaved image-text inputs.
Therefore, we focused on the auto-regressive architecture due to its flexibility and ease of quantization/deployment.
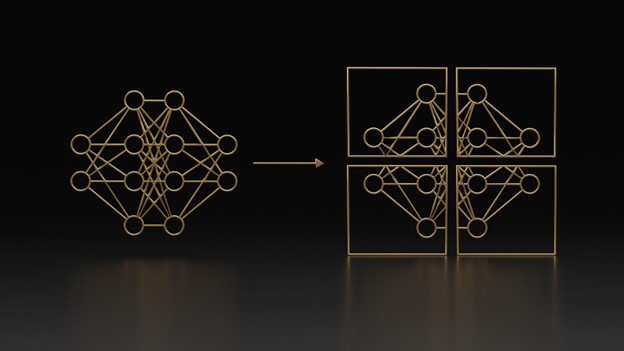
Figure 1 shows that auto-regressive VLMs consist of three components: a visual encoder, an LLM, and a projector that bridges the embeddings from the two modalities. The model takes visual and text input and generates text outputs.
Unfreezing the LLM is essential
There are two popular ways to augment a pretrained, text-only LLM with visual inputs: fine-tune LLMs on the visual input tokens or freeze the LLM and train only the visual input projector as prompt tuning.
The latter is attractive as freezing the LLMs prevents the degradation of the pretrained, text-only LLM. Nonetheless, updating the base LLM is essential to inheriting some appealing LLM properties like in-context learning.
We observed the following:
- Training only the projector during SFT leads to poor performance despite using a high-capacity design. It is more rewarding to fine-tune LLM during SFT.
- Interestingly, freezing the LLM during pretraining does not affect zero-shot performance but degrades in-context learning capabilities.
- When using a small-capacity projector (a linear layer instead of a transformer block), the accuracy is slightly better (comparing c and d). We hypothesize that a simpler projector forces the LLM to learn more when handling visual inputs, leading to better generalization.
Given these observations, we used a simple linear projection layer to fine-tune the LLM during pretraining and instruction-tuning in later studies.
Interleaved image-text data is essential
Our goal is to augment the LLM to support visual input instead of training a model that only works well on visual language inputs. It’s essential to preserve the text-only capabilities of LLMs.
Data curation and blending are key factors for pretraining and instruction tuning. There are two data formats:
- Image-text pairs (that is, image and its caption): <im1><txt1>, <im2><txt2>
- Interleaved image-text data: <txt1><im1><txt2><txt3><im2><txt4>
Image-text pairs
Using image-text pairs like in the COYO dataset for pretraining can lead to catastrophic forgetting. The text-only accuracy (MMLU) degrades by 17.2%.
Noticeably, the 4-shot accuracy is even worse than zero-shot, showing that the model cannot properly do in-context learning for visual language inputs (probably because it never sees more than one image during pretraining).
We believe the catastrophic forgetting is due to the distribution of text-based captions, which are generally short and concise.
Interleaved image-text
On the other hand, using an interleaved image-text dataset like MMC4 has a much closer distribution compared to a text-only corpus. When using the interleaved data for pretraining, the degradation on MMLU is only ~5%.
With proper instruction tuning, this degradation can be fully recovered. It also enables visual in-context learning, leading to a higher 4-shot accuracy compared to zero-shot, which is a highlight of VILA.
Data blending
Data blending improves pretraining to combine the best of both worlds. Blending the interleaved corpus and the image-text pairs enables you to introduce more diversity in the corpus while also preventing severe degradation.
Training on both MMC4+COYO further boosts the accuracy on visual language benchmarks.
Recover LLM degradation with joint SFT
Despite the interleave data helping to maintain the text-only capability, there is still a 5% accuracy drop.
A potential approach to maintain the text-only capability would be to add a text-only corpus (the one used in the LLM pretraining). However, such a text corpus is usually proprietary even for open-source models. It is also unclear how to subsample the data to match the scale of a vision-language corpus.
Luckily, we found that the text-only capabilities are only temporarily hidden and not forgotten. Adding text-only data during SFT can help bridge the degradation despite using a much smaller scale than the text pretraining corpora (usually trillion-scale).
We observed that blending in the text-only SFT data bridges the degradation of text-only capability and improves the visual language capability. We speculate that the text-only instruction data improves the model’s instruction-following capability, which is also important for visual language tasks.
Interestingly, the benefit of blending in COYO data is more significant with joint SFT. We believe that with joint SFT, the model no longer suffers from text-only degradation when pretrained with short captions, thus unlocking the full benefits of better visual diversity.
Image resolution matters, not the number of tokens
Increasing the resolution from 224 to 336 can improve the TextVQA accuracy from 41.6% to 49.8%.
However, a higher resolution leads to more tokens per image (336×336 corresponds to 576 tokens/image) and a higher computational cost, which is even worse for video understanding given the limited context length. We have a LongLoRA technique to extend the context length, which we plan to combine. It also limits the number of demonstrations for in-context learning.
Luckily, the raw resolution matters more than the number of visual tokens/image. We can use different projector designs to compress the visual tokens. We tried a downsample projector, which simply concatenated every 2 × 2 tokens into a single one and used a linear layer to fuse the information. It reduced the #tokens to 144 under the 336 resolution, even smaller than the 224+linear setup.
Nonetheless, the TextVQA accuracy is higher (46% vs. 41.6%) despite still being 3% worse compared to the 336+linear setup, showing a large redundancy in the image tokens. The gap on other datasets, such as OKVQA and COCO, is smaller since they usually require higher-level semantics.
In our initial publication we did not apply any token compression in the main results. However, in this release, we include this token compression technique for models at all sizes.
Data quality is more important than data quantity
Our experiments showed that scaling up pretraining data from 25M to 50M doesn’t provide much benefit. However, adding ~1M of high-quality data improves benchmark results. Therefore, data quality is much more important than data quantity.
To train VILA with high performance but limited computing resources, we focused more on data quality rather than data quantity. For example, according to the CLIP score, we only chose the top 5% of the COYO-700M dataset for text-image pairs. We also filtered top-quality data for the video-captioning dataset and added it to our dataset mixture.
VILA deployment
VILA is friendly to quantize and deploy on the GPU. It augments the LLM with a visual token but doesn’t change the LLM architecture, which keeps the code base modular.
We quantized VILA using 4-bit AWQ and deployed it on an NVIDIA RTX 4090 and Jetson Orin. For more information, see Visual Language Intelligence and Edge AI 2.0.
The AWQ quantization algorithm is suitable for multi-modal applications since AWQ does not require backpropagation or reconstruction, while GPTQ does. Thus, it has better generalization ability to new modalities and does not overfit to a specific calibration set. We only quantized the language part of the model as it dominates the model size and inference latency. The visual part takes less than 4% of the latency.
AWQ outperforms existing methods (RTN, GPTQ) under zero-shot and various few-shot settings, demonstrating the generality of different modalities and in-context learning workloads.
Performance
| Model | VQA-V2 | GQA | VQA – T | ScienceQA – I | MME | SEED- I | MMMU val | MMMU test |
| LLaVA-NeXT-34B | 83.7 | 67.1 | 69.5 | 81.8 | 1631 | 75.9 | 51.1 | 44.7 |
| VILA1.5-40B | 84.3 | 64.6 | 73.5 | 87.4 | 1727 | 75.7 | 51.9 | 46.9 |
| Model | Precision | VQA-V2 | GQA | VQA – T | ScienceQA – I | MME | SEED- I | MMMU val | MMMU test |
| VILA1.5-13B | fp16 | 82.8 | 64.3 | 65 | 80.1 | 1570 | 72.6 | 37.9 | 33.6 |
| VILA1.5-13B | int4 | 82.7 | 64.5 | 64.7 | 79.7 | 1531 | 72.6 | 37.8 | 34.0 |
| Llama-3-VILA1.5-8B | fp16 | 80.9 | 61.9 | 66.3 | 79.9 | 1577 | 71.4 | 36.9 | 36 |
| Llama-3-VILA1.5-8B | int4 | 80.3 | 61.7 | 65.4 | 79.0 | 1594 | 71.1 | 36.0 | 36.1 |
| Model | Precision | NVIDIA A100 GPU | NVIDIA RTX 4090 | NVIDIA Jetson Orin |
| VILA1.5-13B | fp16 | 51 | OOM | 6 |
| VILA1.5-13B | int4 | 116 | 106 | 21 |
| Llama-3-VILA1.5-8B | fp16 | 75 | 57 | 10 |
| Llama-3-VILA1.5-8B | int4 | 169 | 150 | 29 |
Video captioning performance
VILA has in-context learning capability: prompting with few-shot examples without explicitly describing the task (describing the company, classification and counting, and world knowledge), VILA can automatically recognize the task and make correct predictions.

VILA has good generalization and reasoning capability. It can understand memes, reason over multiple images or video frames, and handle corner cases in driving scenarios.

VILA at NVIDIA GTC 2024
At NVIDIA GTC 2024, we announced VILA to enable efficient multi-modal NVIDIA AI solutions from the edge to the cloud.
On the edge, VILA is efficiently quantized to four bits using AWQ, readily available for download, enabling real-time inference on the NVIDIA Jetson Orin Nano and Jetson AGX Orin platforms. This significantly addresses the challenges of limited energy and latency budgets encountered by robotics and autonomous vehicle applications at the edge. For a comprehensive tutorial, see Visual Language Intelligence and Edge AI 2.0.
VILA and NVIDIA Visual Insight Agent
VILA enhances the NVIDIA Visual Insight Agent (VIA) framework in the cloud, enabling you to create AI agents. These agents assist operational teams by responding to inquiries such as, ‘What occurred in aisle three of the factory?’ For instance, the generative AI-powered agent could instantly provide insights, explaining, ‘At 3:30 p.m., boxes toppled from the shelves, obstructing the aisle.’
Using the VIA framework, you can craft AI agents that process substantial volumes of live or archived video and image data through vision-language models. Whether implemented at the edge or in the cloud, this advanced generation of visual AI agents is set to transform virtually every industry. They enable you to summarize, search, and derive actionable insights from video content using natural language.
For more information, see Staying in Sync: NVIDIA Combines Digital Twins With Real-Time AI for Industrial Automation.

Conclusion
VILA offers an efficient design recipe to augment LLMs toward vision tasks, from training to inference catering. Leveraging the full strength of unfreezing the LLM, interleaved image-text data curation, and careful text data re-blending, VILA has surpassed state-of-the-art methods for vision tasks while preserving text-only capabilities.
VILA has demonstrated strong reasoning capability for multi-image analysis, in-context learning, and zero/few-shot tasks. We hope VILA can help NVIDIA build better multi-modal foundation models with diverse applications in NVIDIA Metropolis, audiovisual, robotics, generative AI, and more.
For more information, see the VILA: On Pre-training for Visual Language Models paper and the /Efficient-Large-Model/VILA GitHub repo.